



はじめに
この記事ではPythonで物体検出をおこないます。
物体検出とは、画像内のどこに何が写っているかを検出する技術のことです。
今回はそんな物体検出を簡単に試すことができる「YOLO v5」をGoogle Colabで動作させます。
なお、この記事のコードは下記で試すことができます。

YOLO v5をGoogle Colabにインストールする
まず、YOLO v5のリポジトリをクローンすることから始めます。google colabで下記のコマンドを実行して、クローンをおこないます。
!git clone https://github.com/ultralytics/yolov5クローン後、動作に必要なライブラリをインストールします。それにはクローンしたリポジトリ内にある、requirements.txt を用います。
%cd /content/yolov5/
!pip install -qr requirements.txt以上でインストールは完了です。
YOLO v5で物体検出をおこなう
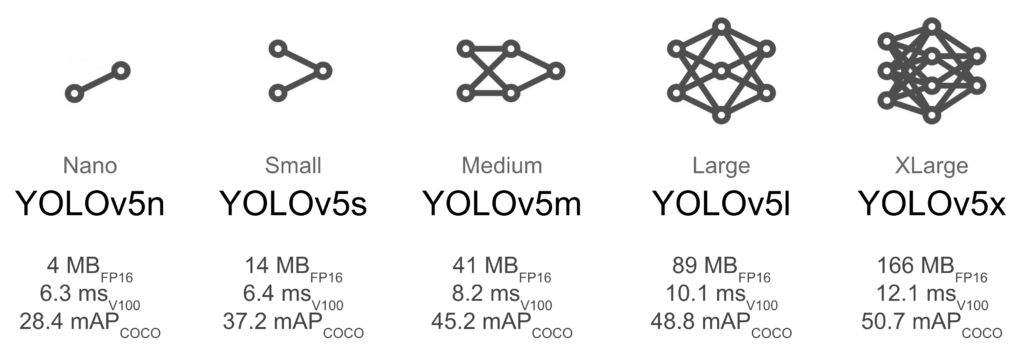
では、実際にYOLO v5で物体検出をおこなってみます。YOLO v5には5種類のモデルが用意されていますが、今回は小さなモデルである YOLOv5s を用いることにします。
物体検出にはこちらの画像を使いました。

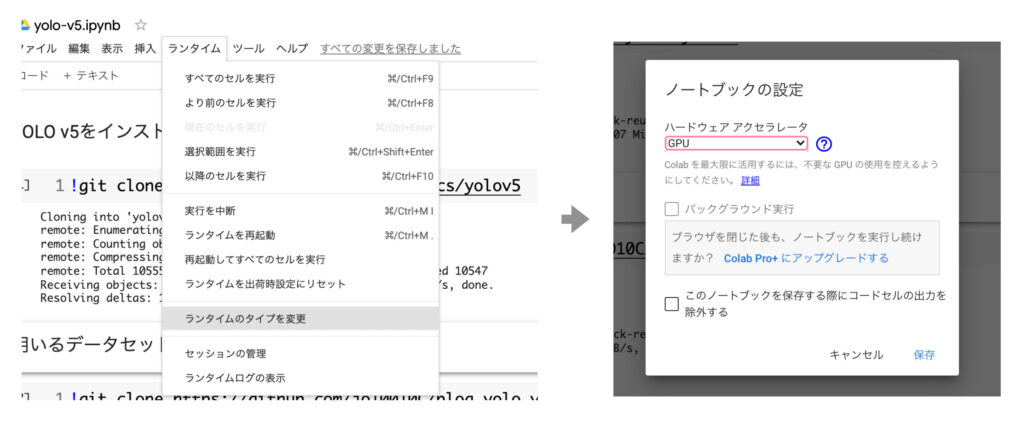
今回はGoogle Colabを使用するので、無料でGPUを使うことができます。
「ランタイム>ランタイムのタイプを変更」から「ハードウェア アクセラレータ」を「GPU」に設定しておきます。
物体検出をするには、クローンしたリポジトリである yolov5 ディレクトリに移動し、以下のコマンドを実行します。
!python detect.py --source {推論に用いる画像のpath} --weights yolov5s.pt --conf 0.3 --name demo --exist-ok上記のコマンド実行後、/runs/detect/demo/ というディレクトリが作成され、そこに物体検出が行われた画像が出力されます。
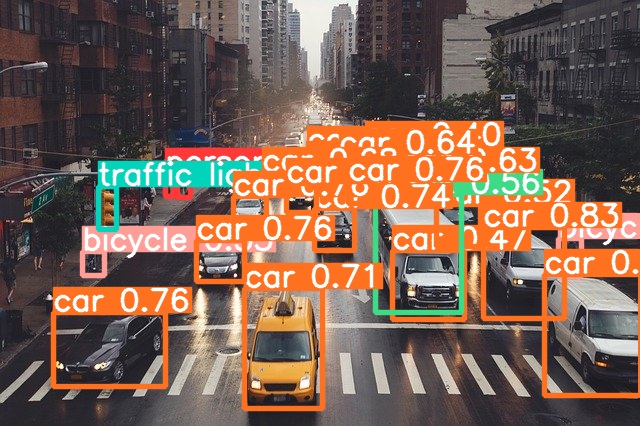
推論後の画像がこちらです。車や信号などを検出しているのがわかります。
YOLO v5の学習方法
画像内から検出したい物体を上手く推論するためには、それ専用のデータセットを用意して、「モデルの学習」をする必要があります。
今回はペンギンを検出できるようにモデルの学習をおこなってみました。
まずは、モデルの学習を行わないで、ペンギンの画像をモデル: YOLOv5sを使って推論してみます。結果は以下のようになりました。

このようにpenguin(ペンギン)ではなく、bird(鳥)と検出されました(まあ、ペンギンは鳥類だから間違いではない……?)。また、重なっていて見にくいですが、banana(バナナ)とも検出されています。
そこで、penguinと検出してくれるようにモデルを学習させてみます。
教師データを作成する
モデルの学習を行うために、画像のどれがペンギンであるかという教師データを作成する必要があります。
ペンギンの画像はフリー画像を30枚ほど集めました。(train: 20枚、val: 6枚)
そして、教師データの作成にはlabelImgを用いました。labelImgというライブラリを使用することで、画像内のペンギンを示す矩形座標のtxt情報を簡単に作成することができます。

▼labelImgのインストール方法と使い方はこちら

今回は「penguins」ディレクトリを作成し、そこに画像、ラベリングデータを保存します。また、penguinsディレクトリ配下には、YOLOv5の学習時に使用する、penguin.yaml というファイルも配置します。
penguins
| - penguin.yaml
| - train(教師データ)
| | - img_・・・.jpg(画像データ)
| | - img_・・・.txt(ラベリングデータ)
| | - img_・・・.jpg
| | - img_・・・.txt
| | - img_・・・.jpg
| ・・・
| - val(検証データ)
| | - img_・・・.jpg
| | - img_・・・.txt
| ・・・
| - test (テストデータ)
| - img_・・・.jpg
| - img_・・・.jpg
・・・penguin.yamlファイルには下記のように、train, val, test フォルダのパス、分類するクラスの数とクラスの情報を記載します。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /content/blog_yolo_v5/penguins/train/
val: /content/blog_yolo_v5/penguins/val/
test: /content/blog_yolo_v5/penguins/test/
# number of classes
nc: 1
# class names
names: ['penguin']学習をおこなう
学習は下記のコマンドを実行するだけです。
!python train.py --img 640 --batch 16 --epochs 200 --data {penguin.yamlのpath} --weights yolov5s.pt学習が終了すると、学習後のパラメータが /runs/train/exp/weight/というディレクトリに作成されます。best.pt が学習中でもっとも精度が高かったもの、last.ptが最後のepocのものになります。

また、TensorBoardを利用すると学習の様子をグラフで確認できます。
# tensorboardの表示
%load_ext tensorboard
%tensorboard --logdir runs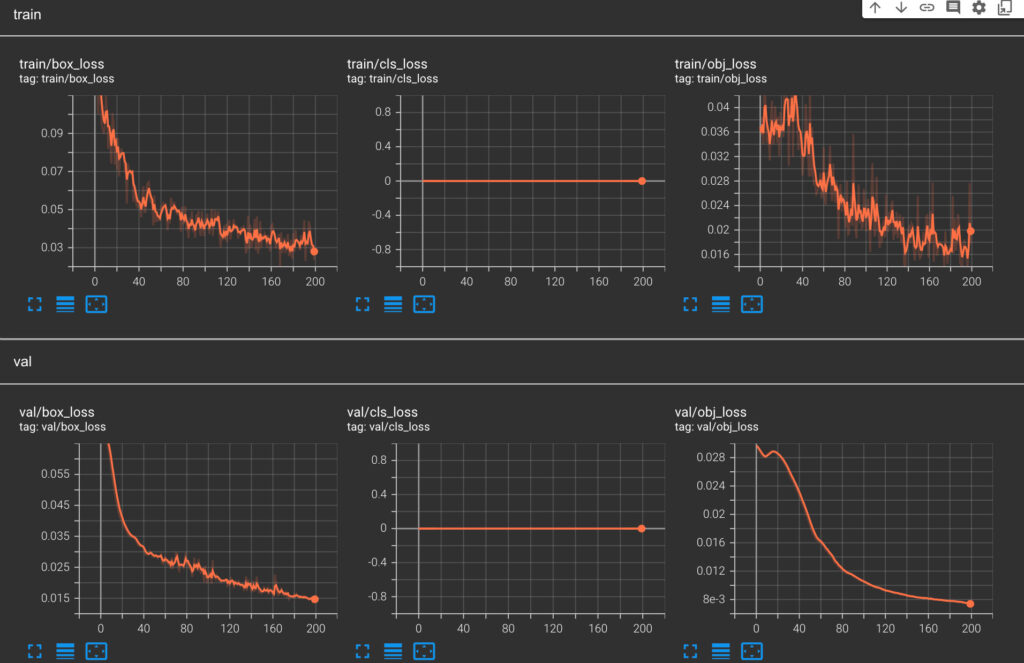
推論をおこなう
では、学習後のモデルを用いて、ペンギンの物体検出を行ってみましょう。
!python detect.py --source {testディレクトリのpath} --weights {best.ptのpath} --conf 0.25 --name trained_exp --exist-ok --save-conf結果はこのようになりました。

penguin(ペンギン)として認識してくれていますね。
今回はYOLOv5sという小さめのモデルを使用しています。もっと大きなモデルを使用したり、教師データの数を増やしてみると、さらに精度の良いモデルが作成できるかもしれません。

