



はじめに
YOLO等の深層学習で物体検出をおこなうには、学習画像データセットが必要です。つまり、画像の「どの部分」に「何が」写っているかという情報を用意する必要があります。
labelImgというツールを使うと、そのような学習画像データセットが簡単に作成できます。
この記事では、labelImgのインストール方法と使い方について述べます。
▼実際にlabelImgを用いて作成したデータセットで、YOLOの学習はこちらでおこないました。

labelImgのインストール(Windows, Linux)
Windows, Linuxの場合、下記のリンクから最新のパッケージ(ページ 一番下のバージョン)をダウンロードし、解凍します。


その後、展開後のフォルダで
./labelimgで起動します。
labelImgのインストール(Mac)
labelImgのリポジトリをクローンし、必要なライブラリをインストールします。
# リポジトリのクローン
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
# 必要なライブラリをインストール
brew install qt
brew install libxml2
pip install pyqt5 lxml
make qt5py3その後、
python labelImg.pyで起動します。
labelImgの使い方
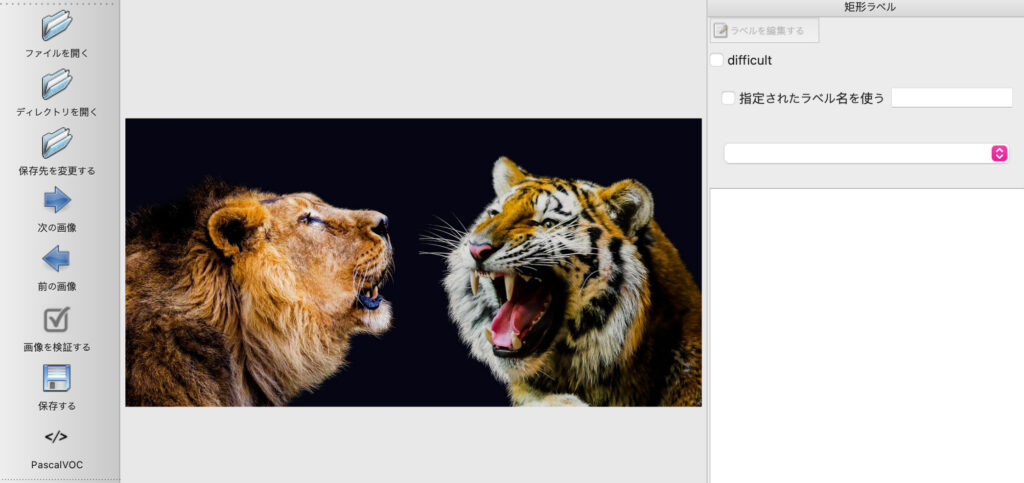
今回はこちらの画像使って、学習データを作成します。

必要なラベルは、
- lion(ライオン)
- tiger(虎)
となります。
(画像は「target_img/lion_tiger.jpg」に配置されているものとします。)
1. まずは、学習に使用するラベルリストを指定してあげる必要があります。
labelImgをインストールしたフォルダの中にある「data/predefined_classes.txt」を、必要なラベル一式に書き換えます。

2. labelImgを起動します。
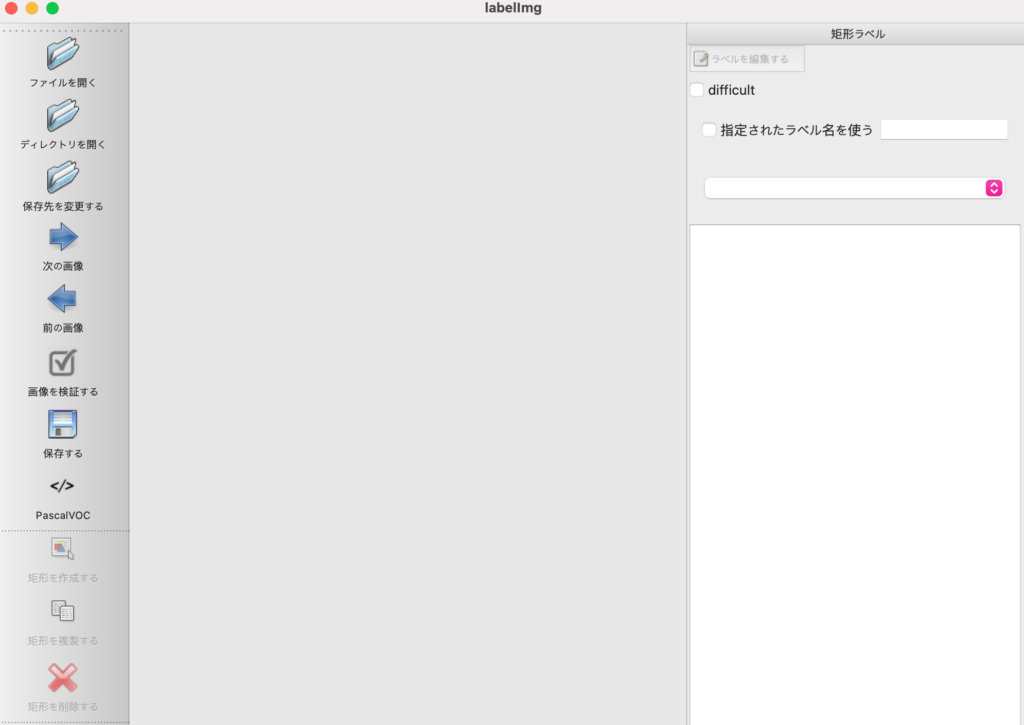
3.「ディレクトリを開く」をクリックして、対象の画像が配置されているディレクトリを指定します。すると、そのディレクトリに保存されている画像が読み込まれます。
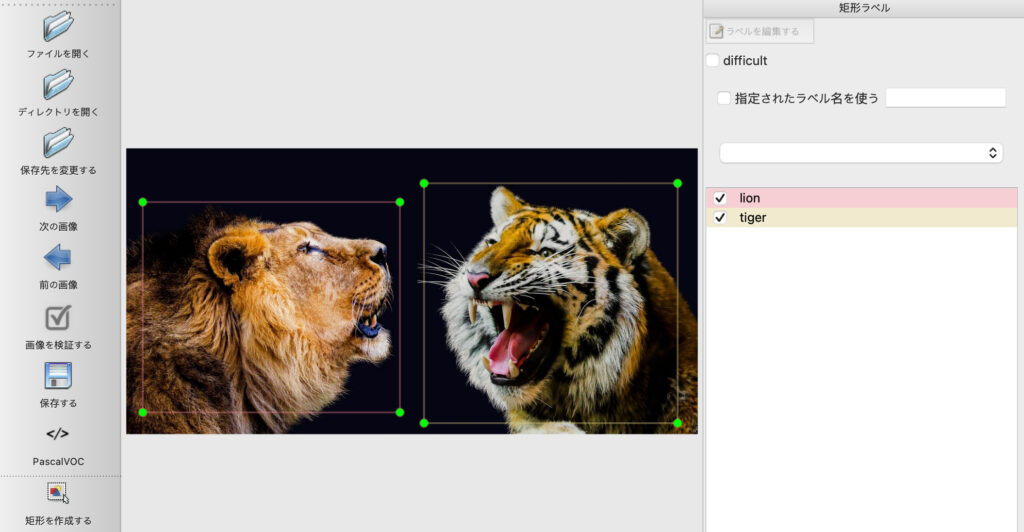
4. 今回はYOLOで学習する専用のデータセットを作成するので、サイドバーにある「保存する」ボタン下の「PascalVOC」をクリックし、「YOLO」に変更します。あとは、サイドバー左下にある「矩形を作成する」から画像に矩形、ラベルを選択します。
5. 最後に「保存する」ボタンから保存すれば、学習データの完成です。
保存が完了すると、対象の画像が配置されているディレクトリに、「classes.txt」、「lion_tiger.txt」(画像と同じ名前のtxtファイル)が新しく作成されます。
大切なのは後者のファイルで、画像の「どの部分」に「何が」写っているかという情報が記載されています。

また、labelImgのショートカットキーは下記の通りとなっています(macの場合は、Ctrl → Command⌘)。
| Ctrl + u | ディレクトリからすべての画像をロード |
| Ctrl + r | デフォルトの注釈ターゲットディレクトリを変更 |
| Ctrl + s | 保存 |
| Ctrl + d | 現在のラベルとrectボックスをコピー |
| Ctrl + Shift + d | 現在の画像を削除 |
| スペース | 現在の画像に検証済みのフラグを立てます |
| w | 長方形ボックスを作成 |
| d | 次の画像 |
| a | 前の画像 |
| del | 選択したrectボックスを削除 |
| Ctrl++ | Zoom in |
| Ctrl– | Zoom out |
| ↑→↓← | 選択したrectボックスを矢印キーで移動 |
これで、YOLO等の深層学習で物体検出の学習がおこなえますね。
▼ YOLOの学習方法はこちら

