


機械学習システム設計の概要
多くのエンジニアは、ロジスティック回帰やニューラルネットワークなどのML(機械学習)アルゴリズムを、MLシステム全体と考えがちです。しかし、実際の製品環境でのMLシステムは、モデル開発だけでなく、さまざまな要素を含んでいます。
MLシステムはふつうは複雑で、データ管理のためのデータスタック、何百万ものユーザーに利用可能にするためのサービングインフラストラクチャ、提案されたシステムのパフォーマンスを評価する評価パイプライン、モデルのパフォーマンスが時間とともに低下しないようにするためのモニタリングなど、多数のコンポーネントから構成されています。
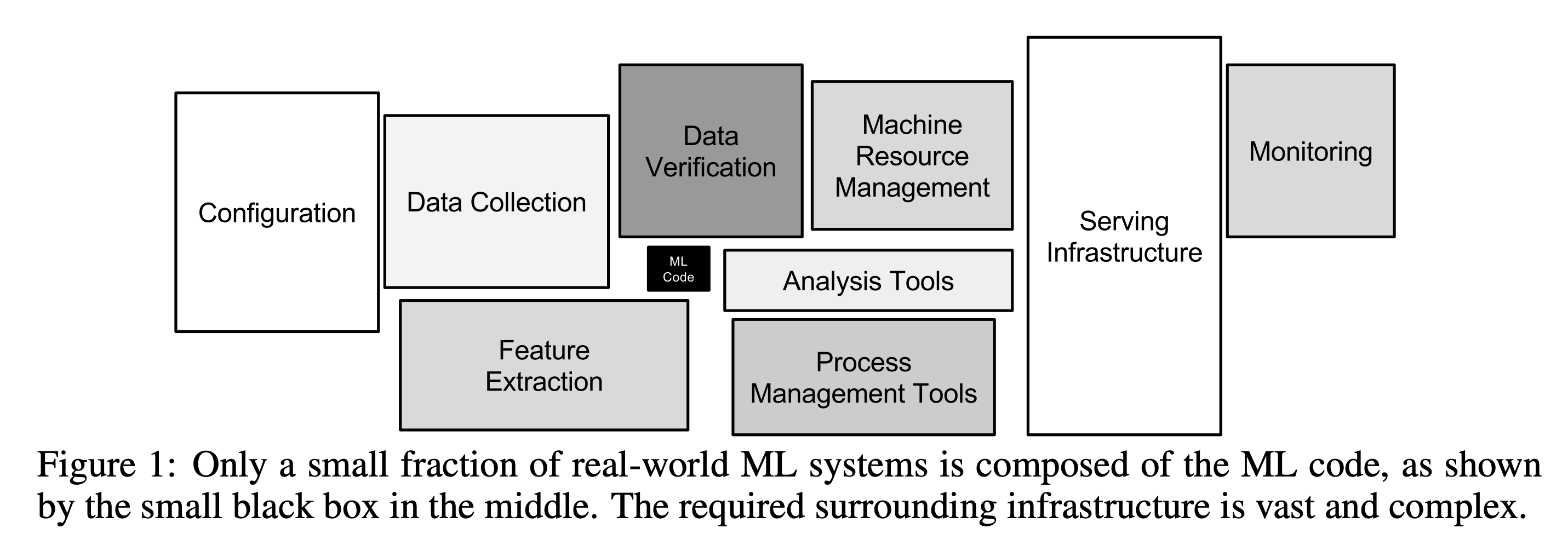
例えば、MLシステム設計の面接では、映画の推薦システムやビデオ検索エンジンを設計するように求められるかもしれません。これには決まった正解はありません。面接官は、あなたの思考プロセス、さまざまなMLトピックに対する深い理解、エンドツーエンドのシステムを設計する能力、さまざまな選択肢のトレードオフに基づいた設計選択を評価したいと考えているはずです。
ただ、複雑なMLシステム設計ではフレームワークに従うことが重要です。このフレームワークは主に以下のステップで構成できます。
- 要件の明確化
- 問題を ML タスクとして組み立てる
- データの準備
- モデル開発
- 評価
- 導入とサービス提供
- 監視とインフラストラクチャ
フレームワークの各ステップの内容をみていきましょう。
要件の明確化
MLシステムの要件を明確にしないことには、正しく設計を行うことはできません。以下は考慮するべき内容の例です。
- ビジネス目標: 例えば宿泊施設を推奨するシステムを作るよう求められた場合、目標は予約数の増加と収益の増加の二つが考えられます。
- システムがサポートするべき機能: 例えば、ビデオ推薦システムを設計するよう求められたとしましょう。ユーザーが推奨ビデオに「いいね👍」や「嫌い👎」をつける必要があるかもしれません。それは訓練データのラベル付けに使用できるからです。
- データ: データソースは何でしょう?データセットの大きさは?データはラベル付けされていますか?
- 制約: 利用可能な計算能力はどれくらいでしょうか? クラウドベースのシステム? それともデバイス上で動作するシステム? モデルは時間の経過とともに自動的に改善する必要がありますか?
- システムの規模: ユーザーは何人程度ですか? 取り扱う項目(ビデオ推薦システムならビデオなど)は何個? これらの指標の成長率はどうですか?
- パフォーマンス: 予測はどれくらい高速である必要がありますか? リアルタイムの予測が期待されているますか? 精度と遅延のどちらが優先されるべき?
上記はあくまでも例であり、プライバシーや倫理など、他のトピックも重要になる可能性があります。
問題を MLタスクとして組み立てる
特定の問題をMLタスクとして組み立てるために、以下の内容を考える必要があります。
- 適切な ML目標は何ですか? さまざまな ML目標をどのように比較するのでしょうか? 長所と短所は何ですか?
- ML の目的を考慮した場合、システムの入力と出力は何ですか?
- MLシステムに複数のモデルが関与している場合、各モデルの入力と出力は何ですか?
- タスクは教師あり、教師なしのどちらの方法を使用する必要がありますか?
- 回帰モデルと分類モデルのどちらを使用して問題を解決する方が良いでしょうか? 分類の場合、2値分類ですか、多クラス分類ですか? 回帰の場合、出力範囲はどれくらいですか?
ML目標の定義
ビジネス目標は、売上を 20% 増加させることや、ユーザー維持率を向上させることなどです。しかし、単に「売上を 20% 増加させます」と言ってモデルをトレーニングすることはできません。ビジネス目標を明確に定義されたML目標に変換する必要があります。
| アプリケーション | ビジネス目標 | ML目標 |
|---|---|---|
| イベントチケット販売アプリ | チケットの売り上げを増やす | イベント登録数を最大化する |
| ビデオストリーミングアプリ | ユーザーエンゲージメントを高める | ユーザーが動画の視聴に費やす時間を最大化する |
| 広告クリック予測システム | ユーザーのクリック数を増やす | クリックスルー率を最大化する |
| ソーシャルメディアプラットフォーム上の有害なコンテンツの検出 | プラットフォームの安全性を向上させる | 特定のコンテンツが有害かどうかを正確に予測する |
| 友人推薦システム | ユーザーのネットワーク拡大率を高める | 形成されるユーザー同士の接続の数を最大化する |
システムの入力と出力の指定
ML目標を決定したら、システムの入力と出力を定義する必要があります。例えば、ソーシャルメディア プラットフォーム上の有害なコンテンツ検出システムの場合、入力は投稿であり、出力はこの投稿が有害であるとみなされるかどうかです。
場合によっては、システムが複数の ML モデルで構成される場合があります。その場合、各 ML モデルの入力と出力を指定する必要があります。例えば、有害なコンテンツの検出では、あるモデルを使用して暴力を予測し、別のモデルを使用してヌードを予測するなどです。システムは、これら 2 つのモデルに基づいて、投稿が有害かどうかを判断します。
適切な ML カテゴリの選択
MLアルゴリズムは次のカテゴリに大別できます。扱う問題に対して、適切なアルゴリズムを選択することが重要です。
以下で主要なMLアルゴリズムについて簡単にまとめます。
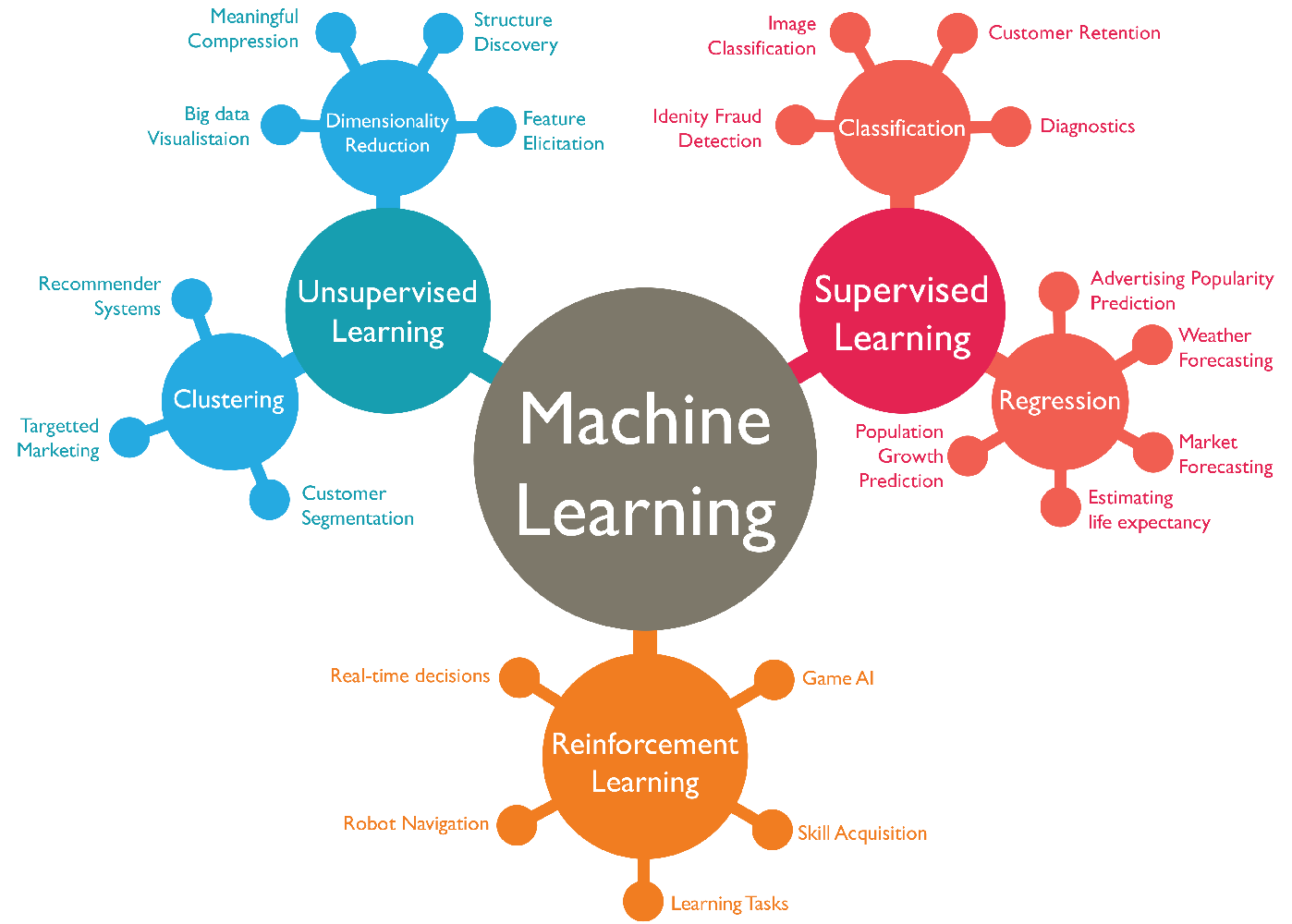
教師あり学習
教師あり学習では、「ラベル付き」のデータセットをもとにモデルを学習させ、その学習データを基にモデルが出力を予測します。ここでの「ラベル付きデータ」とは、入力データに対応する正解データが含まれているものを指します。具体的な手順としては、まず、このラベル付きデータを使ってモデルを学習させ、その後、未知のデータに対して出力を予測させます。
教師あり学習の主な目標は、入力データ $x$ から出力データ $y$ を正確に予測することです。この手法はリスク評価や不正検出、スパムフィルタリングなど様々なアプリケーションで利用されています。
教師あり学習には大きく分けて 分類 と 回帰 の2つのタイプがあります。
分類
分類アルゴリズムは、出力がどのカテゴリに属するかを予測します。具体的には、「はい」or「いいえ」や「男性」or「女性」、「犬」or「猫」などのカテゴリに分ける予測を行います。スパム検出や電子メールのフィルタリングなどが分類の応用例として挙げられます。
よく使われる分類アルゴリズムは以下があります。
- ランダムフォレスト
- 決定木
- ロジスティック回帰
- サポートベクターマシン
回帰
回帰アルゴリズムは、市場の動向や天気の予報など、連続的な値を予測する際に利用されます。具体的には、ある入力(説明変数、特徴量)に基づいて、実数値の出力(目的変数)を予測することを目的としています。
よく使われる回帰アルゴリズムは以下があります。
- 単純な線形回帰
- 多変量回帰
- 決定木ベースの回帰
- リッジ回帰、ラッソ回帰
- サポートベクター回帰
教師なし学習
教師なし学習アルゴリズムの主な目的は、類似性、パターン、違いに基づいて未整理のデータセットをグループ化やカテゴリ分けすることです。モデルは、入力データセットから隠されたパターンを見つけます。ここでモデルに入力されるデータセットにはラベルが付与されていません。
例えば、果物の画像を分類する例を考えます。ここでインプットとなるデータは果物の画像のみで、ラベル(その画像がりんごやオレンジといった情報)は付与されません。この時、モデルは果物の色の違いや形の違いなど、独自のパターンや違いを発見し分類(クラスタリング)を行います。
教師なし学習の代表的なものとして、クラスタリングや次元削減、アソシエーション分析などがあります。
クラスタリング
データの中から似たり寄ったりのデータを見つけ出し、それらをクラスタやグループとしてまとめ上げる作業のことを指します。クラスタリングの目的は、データの中の隠れた構造やパターンを見つけることです。
よく使われるクラスタリングアルゴリズムは以下があります。
- K-Means クラスタリング
- Mean-shift クラスタリング
- DBSCAN クラスタリング
- 階層的クラスタリング
次元削減
次元削減は、データの特徴量(次元)を減少させることによって、データをより扱いやすくしたり、データの構造や関連性を視覚的に理解しやすくする手法です。これにより、計算コストが削減されることが多く、また多次元データの視覚化が可能となります。
よく使われるアルゴリズムは以下があります。
- 主成分分析 (PCA)
- 線形判別分析(LDA)
- t-SNE
- オートエンコーダ
アソシエーション分析
商品やイベントの間の関連性やパターンを探すための手法の一つです。この分析手法は、例えば小売業界での買い物カゴ分析(マーケットバスケット分析)など、どの商品が一緒に購入されやすいかを調査するのに使用されます。
よく使われるアルゴリズムは以下があります。
- Apriori アルゴリズム
- FP-Growth アルゴリズム
- Eclat アルゴリズム
強化学習
強化学習は、上記の教師あり学習や教師なし学習とは少し異質の学習手法です。
強化学習は、エージェントが環境の状態と相互作用を通じて、報酬を最大化するような行動を学習する手法です。ゲームやロボットの制御など、何を選択するかが問題の中心となる状況でよく用いられます。
- エージェント (Agent): 学習や行動をする主体。例えば、ビデオゲームでのキャラクターや実世界でのロボットなど。
- 環境 (Environment): エージェントが行動する場所や状況。エージェントはこの環境内で行動を選択し、その結果として状態が変わることがあります。
- 行動 (Action): エージェントが選択できる選択肢。
- 状態 (State): 環境の現在の状態。エージェントはこの情報を基に次の行動を選択します。
- 報酬 (Reward): エージェントが行動を選択した結果として受け取るフィードバック。この報酬を基に、エージェントは良い行動と悪い行動を学習します。
強化学習の学習プロセスは主に以下となります。
- エージェントが現在の状態を観測します。
- あるポリシー(行動を選択する戦略)に基づいて行動を選択します。
- その行動によって、環境が変わるかもしれません。
- エージェントはその行動に対して報酬(またはペナルティ)を受け取ります。
- エージェントはこの経験を元に、将来の行動選択の参考とするために学習します。
具体例としてゲームの「スーパーマリオ」を考えてみましょう。

- エージェント: マリオ
- 環境: ゲームのステージ
- 行動: 左に移動、右に移動、ジャンプ、など
- 状態: ステージの様々な場所や、敵の位置など
- 報酬: コインを取る、敵を倒す、ゴールするなどでポイントが増える。敵に当たる、穴に落ちるなどでポイントが減る。
マリオはゲームを進める中で、どの行動が良い結果をもたらすか(例: 高い報酬を得る)、またどの行動が悪い結果をもたらすか(例: ライフが減る)を学習していきます。
このように、強化学習は試行錯誤を繰り返しながら、最適な行動を探索・学習していく手法です。
▼ MLアルゴリズムの参考書籍
データエンジニアリング
ML モデルの学習には予測能力のあるデータが必要不可欠です。
それには、データエンジニアリングと特徴量エンジニアリングという 2 つの重要なプロセスを通じて、MLモデルに与えられる高品質なインプットを準備することが大切です。ここではデータエンジニアリングについて確認します。
データエンジニアリングの目的は、データの収集、保存、取得、処理のためのパイプラインを設計、構築することです。
目的を達成するために、考慮するべき点を簡単にまとめます。
データソース
ML システムは、さまざまなソースからデータを処理する必要があります。このデータソースについて十分に理解しておくのは良いことです。ポイントは、
- それは構造化データ?それとも非構造化データ?
- 誰がデータを収集したか?
- データはどの程度きれいか?
- そもそもデータソースは信頼できるものか?
特にデータソースに存在するデータの構造は重要です。データの構造は、構造化データと非構造化データの 2 つのタイプに大別できます。
構造化データは事前定義されたデータスキーマに従うため、データの検索も比較的容易です。表形式で表現できるものは、構造化データとみなすことができます。
非構造化データとは、画像、音声ファイル、ビデオ、テキストなど、基礎となるデータスキーマを持たないデータを指します。
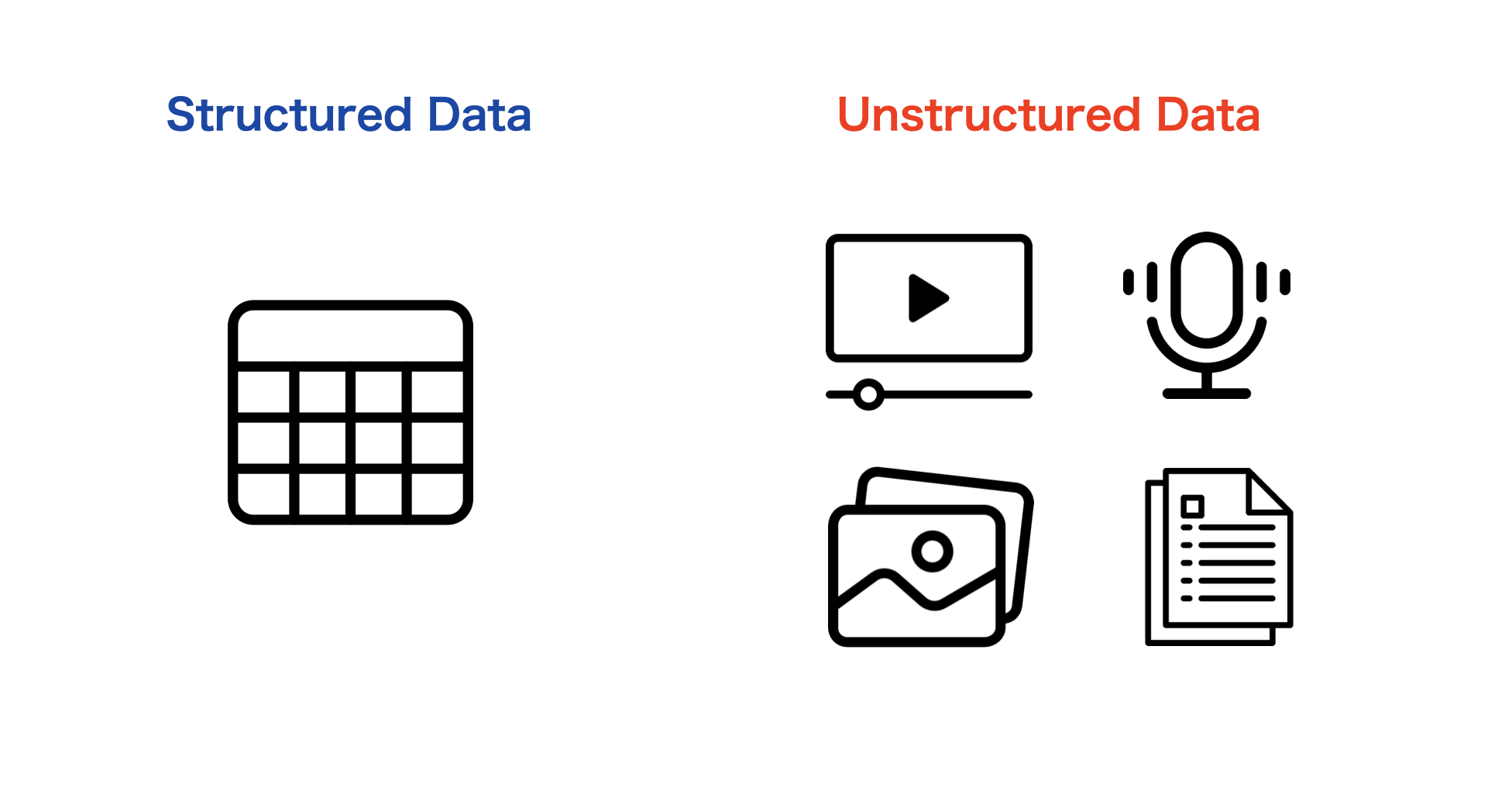
最適なMLアルゴリズムはデータの種類に応じて異なります。構造化データである場合は比較的簡単にモデルの学習が始められ、線形回帰モデルや、決定木ベースモデルなど使用できるMLアルゴリズムのバリエーションは多いです。
非構造化データである場合は、それらでパフォーマンスを上げるのは難しい場合が多く、Deep learning の使用が適切かもしれません。
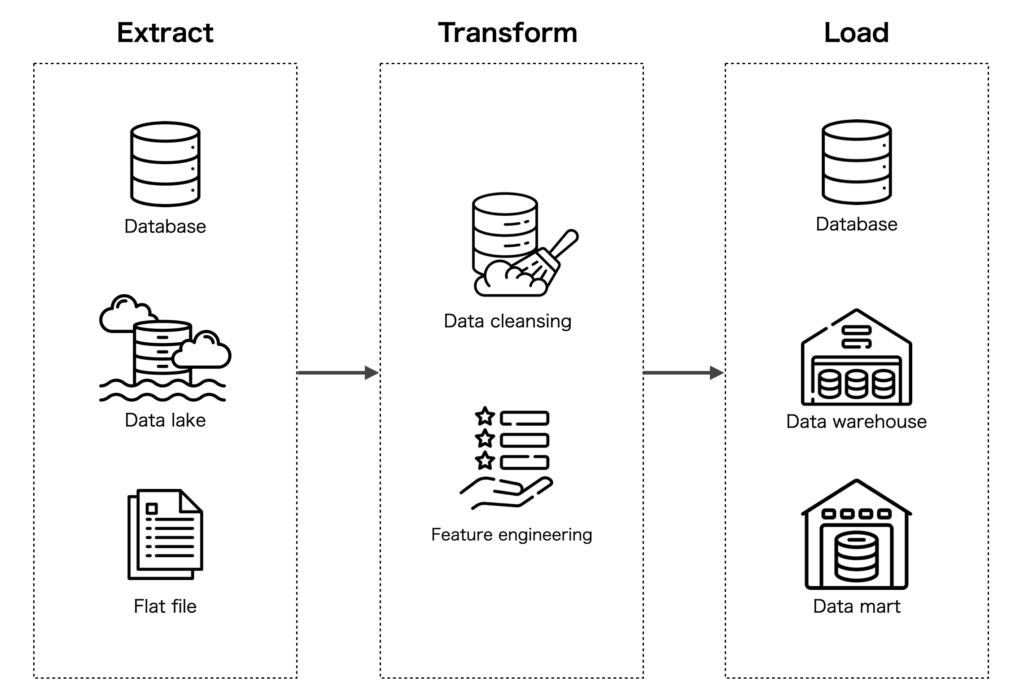
ETL (Extract Transform Load)
ML モデルが適切に学習をおこなうためには、点在しているデータベースやデータソースから集約、クレンジング、マッピングをおこない、学習目的用にデータを集計しておく必要があります。
この、データを 抽出 (Extract)、変換 (Transform)、読込 (Load) する一連の処理を ETL と呼びます(Transform では後述する特徴量エンジニアリングの処理がおこなわれることがあります)。
ETLの文脈では以下のデータの保存方法が登場します。
データレイク
構造化、非構造化データをそのままの形式で格納する大規模なストレージです。データを保存する際に整形の必要がありません。
データウェアハウス
構造化データを集中的に格納し、管理するためのシステムです。データウェアハウスはデータベースの一種ですが、目的別、時系列に大量のデータを蓄積する特徴があります。分析を主な目的としたアーキテクチャであるため、データウェアハウスを利用することで、大量に蓄えたデータに対して効率的な分析や集計が可能です。
データマート
データウェアハウスに蓄えたデータを更に特定の目的別に事前に集計しておくことで、特定用途に対するクエリのレスポンスを向上するために構築します。
データベース
データソースとしてデータベースを使用することは少なくありません。データベースには RDB (relational database) や NoSQL などさまざまな種類があり、それらがどのように機能するかを理解し、収集するデータの特性を考えて適切に使い分けることが重要です。
RDB (relational database)
行と列を持つテーブル形式でデータを保存します。
例: PostgreSQL, MySQL, Oracle
- データの整合性と正確性を保持するための強固なスキーマが存在
- SQL (Structured Query Language) を使用してデータの操作やクエリを行う
- データ間の関係(リレーションシップ)を表すための外部キーなどの機構がある
Key-Value型DB
シンプルなキーと値のペアでデータを保存します。
例: Redis, DynamoDB, Riak
- 高速な読み書きが可能
- スキーマが不要
- キーを知っていれば、迅速に値を取得できる
カラム指向DB
データを列単位で保存し、大量のデータを効率的に読み込むのに適しています。
例: Cassandra, HBase, Google Bigtable
- 書き込みよりも読み取りを優先した操作が高速
- 集約クエリや分析に向いている
- データの圧縮が効果的
グラフDB
データ間の関係性をグラフとして保存します。
例: Neo4j, ArangoDB, OrientDB
- ノードとエッジでデータとその関係性を表現
- 複雑な関係性や階層構造を持つデータに適している
- 連関クエリが高速
ドキュメントDB
ドキュメント形式(例: JSON, BSON)でデータを保存します。
例: MongoDB, CouchDB, RavenDB
- スキーマレスなので、柔軟なデータモデルが可能
- ドキュメント内でネストされたデータ構造を持つことができる
- よく使われる操作は、ドキュメント全体の読み書き
▼ データエンジニアリングの参考書籍
まとめ
- 機械学習システムの構築には、モデル作成以外にも考慮するべきことがたくさんある
- 考える問題を適切なMLタスクに変換してやることが大事
- MLアルゴリズムは種類が豊富で、扱う問題に沿ったものを選択する
- データエンジニアリングを行ない、目的に合ったデータの保存形式をとることが大切

